「Googleドキュメント」アプリでカンタンOCRで文字のデータ化
OCRとは、(Optical Character Recognition/Reader、オーシーアール、光学的文字認識)の事です。
画像の文字情報を、テキストデータとして読み込んで出力する機能。
スキャナーや単独のソフトのOCRソフトは売られていますが、GoogleDriveで十分に利用することができます。
無料のOCRソフトなども使ったことがありますが、微妙な文字化けが多くて手直しが面倒です。
わたしがおススメするのは、GoogleDriveから利用する「Googleドキュメント」です。
※GoogleIDを獲得して利用してみましょう。費用はかかりません。
画像のページ読込から、テキストデータへの変換手順
手順
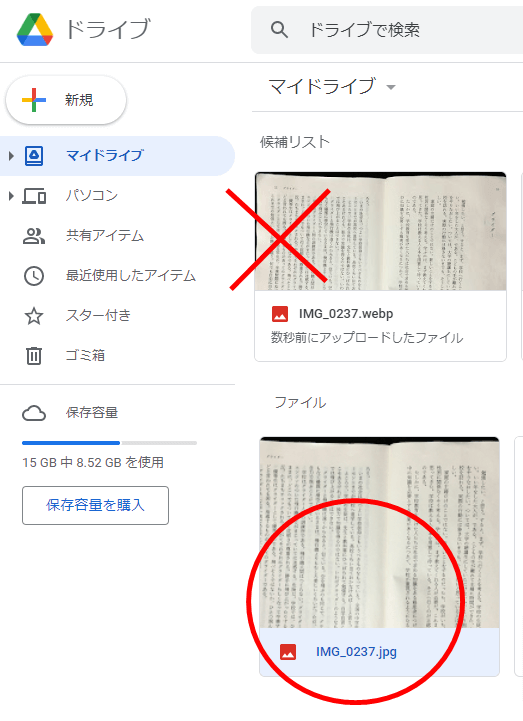
1.GoogleDrive にテキストを読み込みたい画像を保存する
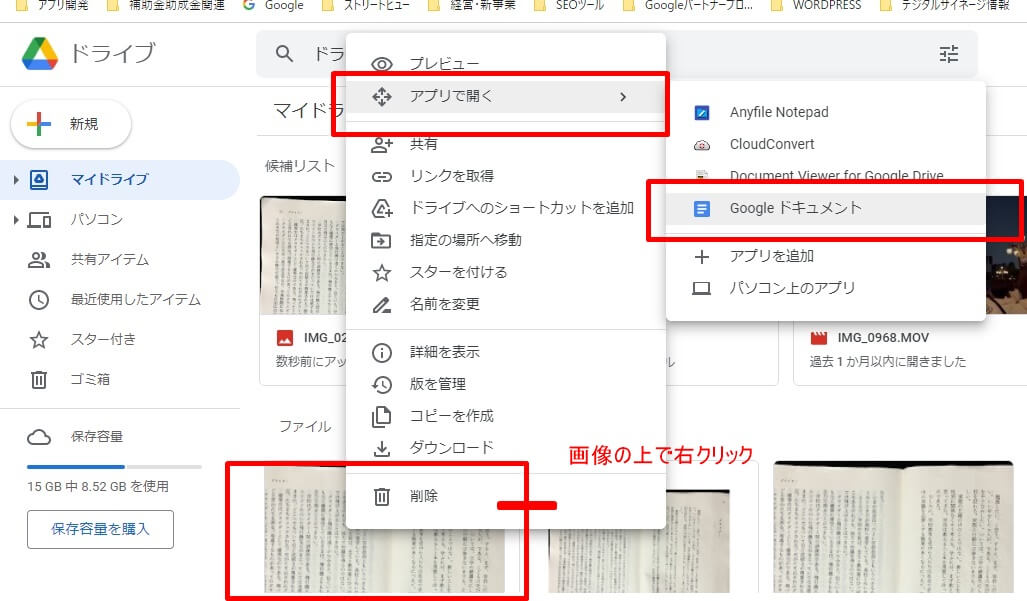
2.ファイルの上で右クリック、「アプリで開く」→「googleドキュメント」の順にクリック
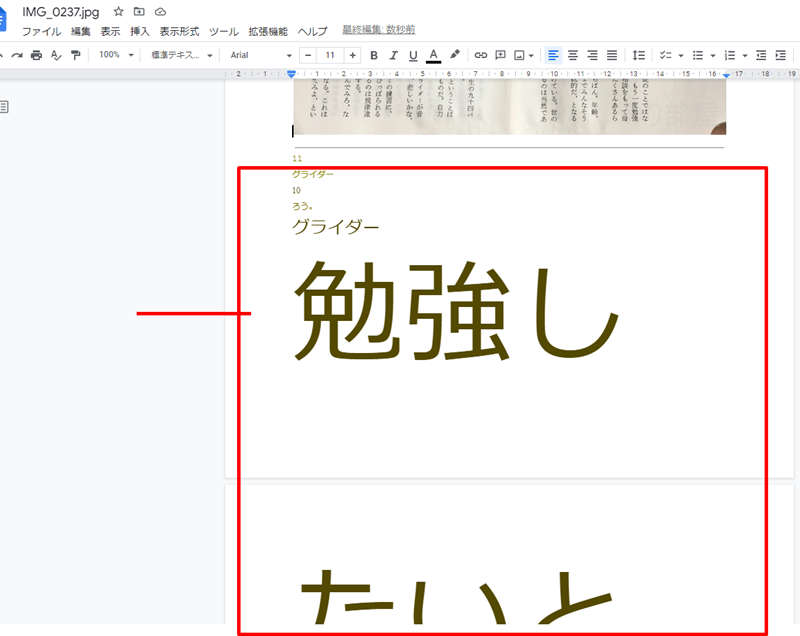
3.Googleドキュメントが立ち上がって、画像とテキストデータが表示される
4.テキストは全てドラックして、コピー
5. テキストエディタに貼り付ける。 完了です。
それでは図入りで説明しましょう。
1.GoogleDrive にテキストを読み込みたい画像を保存します。
使用するファイル形式は、jpeg、png、PDFを使用しましょう。webpはダメな様です。
2.保存したファイルの上で右クリック、「アプリで開く」→「googleドキュメント」の順にクリック
3.Googleドキュメントが立ち上がって、画像とテキストデータが表示されます。
この場合文字が巨大になったので、全部をドラッグしてテキストエディタに貼り付けました。
4.テキストは全てドラックして、コピー
5. テキストエディタに貼り付ける。・・・文字取り出し終了です。
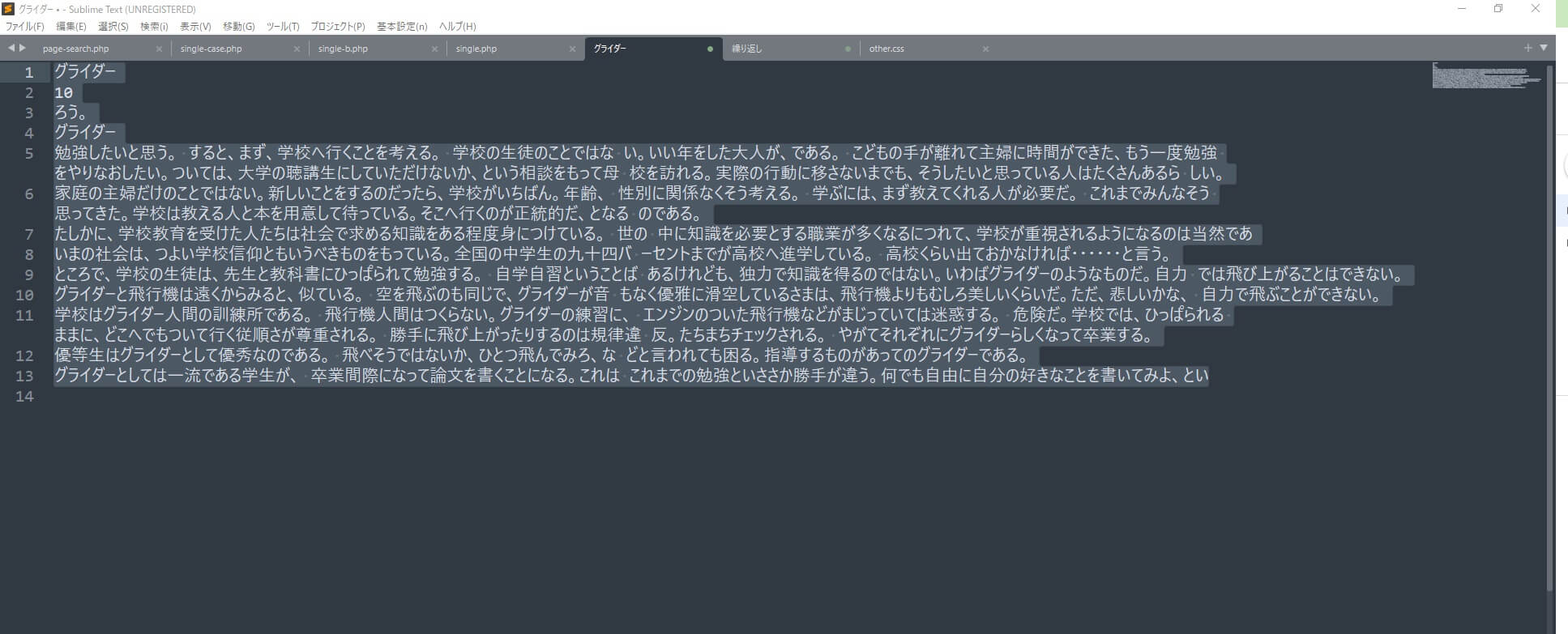
画像からテキストを取り出せたのですが、念のため内容は確認しましょう。
文字取り出し後は、必ず確認が必要です。
文章の本文を変換するだけなら、あまりエラーは出ないんですが、多少の誤字はあります。
出力したテキストを、一度読んでみて、おかしな文字変換が無いかを確認しましょう。
6.お世話になっておる「文章校正ツール」を開く

7.テキストをコピペして、チェックしてもいましょう。
8.変な部分は、修正してからテキストを利用しましょう。
デザイン処理された文字画像を読み込むと、データ化したテキストの順番がおかしくなっていることがあります。
これも、一度読んで確認したうえで、文章を正しく並び替えてあげましょう。